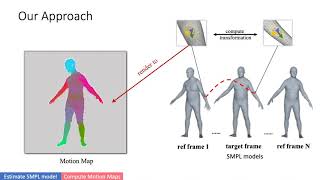
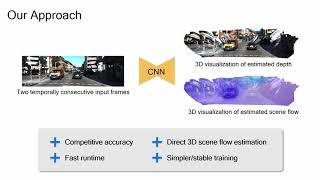
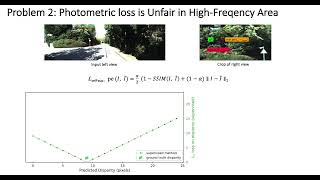
Overview Brief: Authors: Feitong Tan, Hao Zhu, Zhaopeng Cui, Siyu Zhu, Marc Pollefeys, Ping Tan Description: Previous methods on estimating ... Authors: Chen, Xingyu; Li, Thomas H; Zhang, Ruonan; Li, Ge* Description: We present two versatile methods to generally ...
Self Supervised Human Depth Estimation From Monocular Videos - Topic Topic Background
This expanded guide maps Self Supervised Human Depth Estimation From Monocular Videos through quick context, useful references, alternate wording, and broader search ideas while keeping the content simple to scan and easy to expand.
In addition, this page also connects Self Supervised Human Depth Estimation From Monocular Videos with for broader topic coverage.
Topic Topic Background
Authors: Chen, Xingyu; Li, Thomas H; Zhang, Ruonan; Li, Ge* Description: We present two versatile methods to generally ... Please see the arXiv page for more details: by Clément Godard, Oisin Mac Aodha and Gabriel ... Authors: Qi Dai, Vaishakh Patil, Simon Hecker, Dengxin Dai, Luc Van Gool, Konrad Schindler Description: We present a ...
Reference Reader Notes
Authors: Qi Dai, Vaishakh Patil, Simon Hecker, Dengxin Dai, Luc Van Gool, Konrad Schindler Description: We present a ... Authors: Feitong Tan, Hao Zhu, Zhaopeng Cui, Siyu Zhu, Marc Pollefeys, Ping Tan Description: Previous methods on estimating ...
Context Quick Guide
This section introduces Self Supervised Human Depth Estimation From Monocular Videos with the most useful background points and a simple path into the rest of the page.
Overview What to Know
The key details usually include definitions, examples, comparisons, requirements, limitations, and updated references.
Important details found
- Authors: Feitong Tan, Hao Zhu, Zhaopeng Cui, Siyu Zhu, Marc Pollefeys, Ping Tan Description: Previous methods on estimating ...
- Authors: Chen, Xingyu; Li, Thomas H; Zhang, Ruonan; Li, Ge* Description: We present two versatile methods to generally ...
- Authors: Qi Dai, Vaishakh Patil, Simon Hecker, Dengxin Dai, Luc Van Gool, Konrad Schindler Description: We present a ...
- Please see the arXiv page for more details: by Clément Godard, Oisin Mac Aodha and Gabriel ...
What this page helps clarify
This format works because it offers important checks for Self Supervised Human Depth Estimation From Monocular Videos when the topic has many possible meanings.
Common Questions
What questions should readers ask about Self Supervised Human Depth Estimation From Monocular Videos?
Check freshness, source quality, related examples, and any requirements or limitations before relying on one answer.
What should be checked first?
Readers should check the main context, important requirements, source freshness, and any details that may change over time.
What should readers do next?
Readers can review the linked topics, compare several sources, and verify important details before acting on the information.
How can readers narrow down Self Supervised Human Depth Estimation From Monocular Videos?
Readers can narrow it by adding location, year, product name, provider, price range, purpose, or the exact problem they want to solve.